2023. 12. 9. 09:40ㆍ기술적 이슈 정리

개요
현재 Payment-lab에서 가장 큰 고민은 결제 승인 데이터의 손실을 최소화하는 것입니다.
payment-lab에서는 사용자의 결제 승인 데이터의 정합성을 최대한 맞추기 위해, 무조건 PG api의 결제 승인 요청이 성공한 다음에 해당 로그를 DB에 기록하는 방식을 채택하고 있습니다.
CA(Consistency, Availablilty)를 최대한 보장하기 위해 결제 승인 프로세스는 동기 방식으로 진행하기에 실제로 결제가 수행되는 시간이 지연될 수 있습니다. 결제 알림의 경우, 사실 결제 승인이 실제로 이루어지기 이전 시점에 수행한다면 사용자의 편의성을 침해하는 경우를 방지할 수 있을 것입니다.
PG사의 결제 서비스 자체가 실패하는 경우는 드물고, MySQL과 같은 관계형 데이터베이스는 일관성과 가용성을 보장하는 매우 견고한 소프트웨어입니다.
또한, 국내 커머스를 기준으로 사실 결제 트래픽이 생각보다 높지 않다는 점을 고려해보면 결제 승인의 처리량 자체가 그렇게 중요하지 않다는 것을 알 수 있습니다. (배민과 같은 배달 애플리케이션은 예외로 두겠습니다…)
하지만 서버는 애플리케이션 코드를 아무리 잘 구성하고, 서버의 사양을 높여도 드물지만 외부 환경의 문제로 장애가 발생합니다. 결제 서비스를 제공하는 서버에서 장애가 발생한다면 다음과 같은 문제가 생길 수 있습니다.
- 사용자의 결제가 중복되어 처리될 수 있다.
- 사용자의 결제가 제대로 처리되지 않는다.
- 사용자의 결제가 제대로 처리 되었으나, 결제 이력이 남지 않는다.
첫 번째 문제의 경우, 이미 이전에 멱등키를 활용(pull request: '주문결제' 정보를 활용하여, 결제 정보 검증 및 멱등키 생성 기능 추가)하여, 2번 이상의 동일한 결제 승인 요청이 들어오더라도 단 한번의 결제 승인을 수행하도록 조치를 취했습니다.
하지만 2, 3번째 문제에 대한 기술적인 대비책은 전혀 존재하지 않는 상황입니다. 하지만, PG사 자체에서 제공하는 결제 이력 검색 서비스와 payment-lab 자체에서 결제 과정을 로그로 제대로 쌓아 놓는다면, 그 로그를 추적하여 결함을 수동으로라도 조치를 취할 수 있습니다.
따라서 우선은 결제 서비스 장애 발생시 복구 대응을 위한 로그를 최소한의 손실로 여러 지점에서 백업을 할 수 있는 시스템을 구현해보자 합니다.
로그(Log)의 정의와 LogBack의 LogAppender
보통 로그(Log)라는 단어를 들으면 대부분의 개발자들은 애플리케이션의 에러를 포함한 시스템 상태를 표현하는 정보가 담겨있는 일련의 문자열을 연상합니다.
하지만, Apache Kafka를 개발한 Jay Kreps는 로그를 ‘가장 단순하게 추상화된 저장소이며, Append-only에 시간 순으로 정렬된 자료구조’라고 정의합니다. 로그는 이벤트 혹은 정보의 집합이며 로그에 담긴 하나의 정보는 레코드(Record)라고 부릅니다. 아래 그림은 여기서 설명하는 로그의 모습을 보여줍니다.
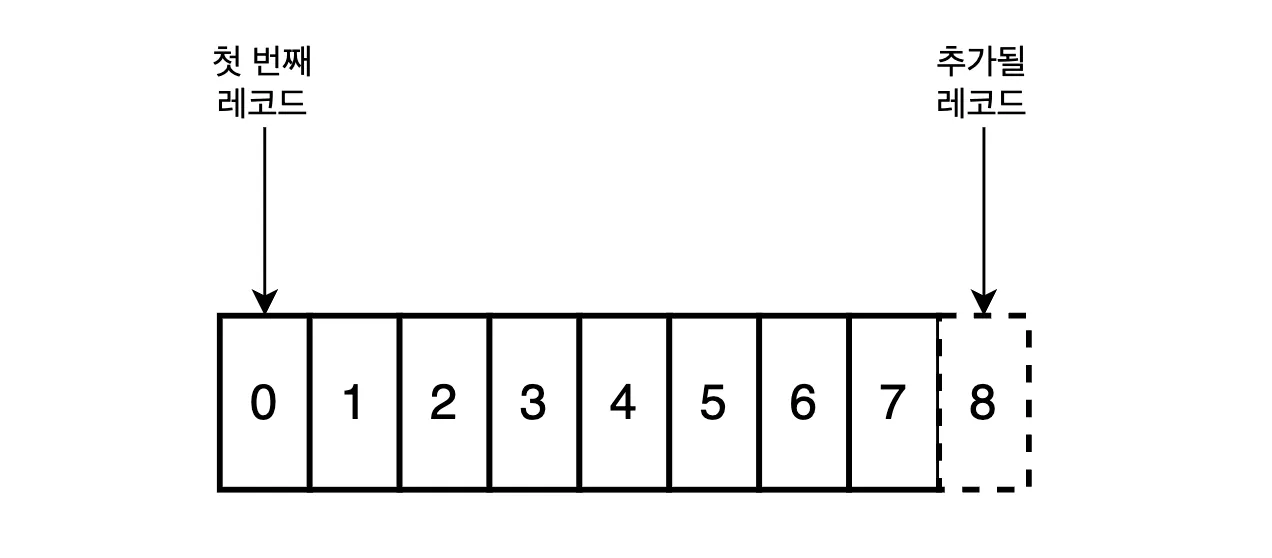
이렇게 로그를 이벤트로 취급하고 append-only로 관리하는 방식은 스프링 프레임워크에서 자주 사용되는 ‘LogBack’ 라이브러리에서도 잠깐 엿볼 수 있습니다.
public interface Appender<E>
extends LifeCycle, ContextAware, FilterAttachable<E> {
/**
* Get the name of this appender. The name uniquely identifies the appender.
*/
String getName();
/**
* This is where an appender accomplishes its work. Note that the argument
* is of type Object.
*
* @param event
*/
void doAppend(E event) throws LogbackException;
/**
* Set the name of this appender. The name is used by other components to
* identify this appender.
*
*/
void setName(String name);
}
Logback 라이브러리는 보통 logback.xml 설정을 통해, 이 Appender 인터페이스의 구현체를 지정합니다. Appender의 종류는 다양하지만 가장 주목할 부분은 ‘AsyncAppender’ 입니다.
public class AsyncAppender extends AsyncAppenderBase<ILoggingEvent> {...}
public class AsyncAppenderBase<E> extends UnsynchronizedAppenderBase<E> implements AppenderAttachable<E> {
AppenderAttachableImpl<E> aai = new AppenderAttachableImpl<E>();
BlockingQueue<E> blockingQueue;
//...
Worker worker = new Worker();
@Override
public void start() {
//....
blockingQueue = new ArrayBlockingQueue<E>(queueSize);
//...
super.start();
worker.start();
}
class Worker extends Thread {
public void run() {
AsyncAppenderBase<E> parent = AsyncAppenderBase.this;
AppenderAttachableImpl<E> aai = parent.aai;
// loop while the parent is started
while (parent.isStarted()) {
try {
List<E> elements = new ArrayList<E>();
E e0 = parent.blockingQueue.take();
elements.add(e0);
parent.blockingQueue.drainTo(elements);
for (E e : elements) {
aai.appendLoopOnAppenders(e);
}
} catch (InterruptedException e1) {
// exit if interrupted
break;
}
}
//....
}
}
}
위 코드는 스프링 프로젝트에서 slf4j로 주입한 Logger로 info(…) 를 호출할 때 동작하는 코드의 일부분을 가져왔습니다. 동작 과정의 설명을 쉽게 풀어쓰기 위해, 로그를 출력할 때 관여하는 부분 위주로 축약해보았습니다.
AsyncAppender가 동작하는 과정을 요약하면, AsyncAppender의 동작 상태(start)를 true로 변경시키고, 해당 appender가 관리하는 blockingQueue를 초기화 시키고, 해당 큐에 worker 스레드를 할당하는 코드입니다.
worker 스레드는 내부 클래스로서 부모 클래스인 AsyncAppenderBase의 blockingQueue에 쌓인 로그 이벤트를 처리하며 로그를 출력합니다.
별도의 worker 스레드를 할당하여 로그를 기록하기 때문에 logger.info(…)를 호출한 요청에 할당된 스레드는 로그 이벤트 처리의 완료여부에 상관없이 바로 다음 비즈니스 로직을 수행하거나, 톰캣 스레드 풀에 스레드를 반납할 수 있습니다.
따라서, AsyncAppender는 트랜잭션 비즈니스 로직을 수행하는 도중에 로그를 출력 함으로써 증가할 수 있는 지연시간을 최대한 줄일 수 있습니다.
하지만 갑작스럽게 서버가 shutdown 될 경우, blockingQueue에서 미처 처리하지 못한 로그 이벤트들은 그대로 누락될 수 있는 리스크를 가지고 있습니다. 그래서 ‘logback manual’ 에서는 queueSize의 크기를 적절히 구성하거나, discardingThreshold 수치를 조절하여 손실되는 로그에 대한 리스크 관리를 할 것을 권장하고 있습니다. 그런데, 이쯤 되면 다음과 같은 의문이 생길 수 있습니다.
로그 손실이 두려우면 AsyncAppender를 안쓰면 되는거 아닌가?
네, 차라리 스프링 부트에서 기본 설정으로 주입해주는 ConsoleAppender 를 사용하는 것이 더 나을 수도 있습니다. ConsoleAppender는 OutputStreamAppender를 확장하여, 파일 입출력 스트림을 직접 라이브러리 내부에서 구현하여 로그를 출력합니다.
그런데 여기서 알아야할 점은 입출력 스트림은 입력과 출력 사이에 ‘버퍼’를 두고 있다는 점입니다. 따라서, ConsoleAppender을 사용해도 결국엔 서버가 갑작스럽게 shutdown 된다면, 버퍼에서 미처 처리하지 못한 로그 이벤트는 분명 존재하므로 근본적인 관점에서는 로그 손실에 대한 해결책이 되진 못합니다.
그리고 무엇보다, payment-lab은 개발자의 편의보다는 사용자의 편의를 더 배려하는 것에 더 높은 우선순위를 두고 있습니다. 즉, 로그 손실이 발생하는한이 있더라도 결제 승인 처리에 지연시간을 감수하여 사용자의 편의를 침해하는 상황은 만들고 싶지 않습니다.
그렇다면, AsyncAppender 를 사용하고도 로그 손실율을 줄이는 방법은 무엇이 있을까요? logback 공식 메뉴얼에서 언급한 것처럼 상황에 맞는 설정을 구성하는 것도 방법 이겠지만, 저는 좀 더 단순한 방법을 활용하기로 했습니다. 그 방법은 다음 문단에서 설명 드리겠습니다.
로그 손실에 대비하는 법: ‘많은 곳에 많이 쌓자’
쉬운 설명을 위해 SSR 기반의 스프링 부트로 구성된 단일 서버와 db 서버만으로 운영되는 커머스 애플리케이션을 예를들어 설명해보겠습니다.
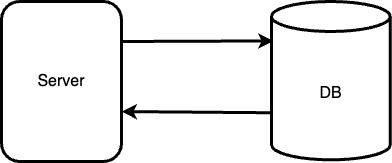
많은 곳에 많이 쌓자는 것은 결국 결제 승인을 수행하는 일련의 과정이 수행되는 지점에 로그를 일일이 다 기록하자는 것입니다. 위의 구조를 참고해보면, Server는 스프링의 logger를 활용하여, server 파일시스템에 로그 파일을 쌓을 수 있습니다.
‘DB’의 경우 대부분의 소프트웨어는 인덱스와 테이블 내의 데이터가 장애 상황에서 안전하게 복구할 수 있도록, WAL(write-ahead-logs) , 즉, 데이터를 변경하기 전에 ‘무엇을 변경해야 하는지’를 로그에 기록합니다. DB의 로그를 많이 쌓기 위해서는 Replication을 활용한 Primary/Secondary 모델을 구성하면 될 겁니다. 이 모델은 서버 인스턴스를 구축하여 직접 구성할 수도 있고, 비싸지만, 그냥 aws RDS를 활용할수도 있습니다.
그럼 서버는? 확장성과 운영 난이도를 고려해보자
그런데, 애플리케이션 서버에서 로그를 많은 곳에 많이 쌓으려면 어떻게 할까요? 당장 생각나는 방법은 그냥 Server를 늘리는 것입니다. 스프링 부트의 직관적인 로그 파일 관리기능을 활용하면, 그냥 서버를 늘리고 애플리케이션을 띄우면 해결 될겁니다. 하지만 이 방법은 여러가지 사이드 이펙트가 있습니다. 몇 가지 나열해보자면..
- 여러 개의 애플리케이션 서버는 결국 로드 밸런서에 의존하게 된다. 즉, 경우에 따라 단일 실패 지점이 될 수도 있고 여러 로드 밸런서를 둔다고 해도 각 로드 밸런서를 통해 기록되는 로그를 동기화하는 방법은 다소 어려울 수 있습니다.
- 지금은 단일 서버에 모든 도메인의 서비스를 구성하고 있다. 하지만, 마이크로서비스로 확장된다면, 나눠지는 서비스의 수가 증가함에 따라 운영 난이도 역시 비례하여 올라갑니다.
이 2가지 요소로 인해 상승하는 운영 난이도는 확장성을 저해하고, 개발자가 서비스를 고도화하는데 제약을 만들어 기술 부채를 발생시키는 요소가 될 리스크도 있습니다.
2번의 케이스의 경우 한 문장으로는 별로 와닿지 않을 수도 있습니다. 하지만 아래 이미지를 참고해보면, 그냥 서버를 확장하는 것은 좋은 방법이 아니라는걸 알게 될겁니다.

그렇다면, 어떻게해야 운영 난이도를 크게 높이지 않으면서 로그를 ‘많은 곳에 많이’ 쌓을 수 있을까요?
최적의 해결책: 로그만을 위한 미들웨어를 만들자
본론을 이야기하기 전에, 잠시 java의 언어가 컴파일 되는 과정의 일부를 이야기 해보겠습니다. java의 컴파일은 ‘자바 언어 스펙에 따라 분석/검증하고, JVM 스펙의 class 파일 구조에 맞는 바이트코드를 만들어내는과정’ 이라 할 수 있습니다.
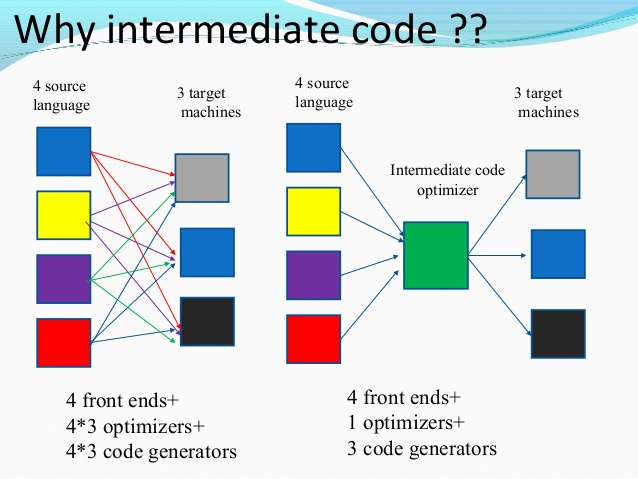
바이트 코드는 JVM 스펙에 맞는 형태이기만 하면 기존 언어가 무엇이든 전부 호환이 되는데 이는 ‘중간 코드(intermediate code)’를 활용하기 때문입니다.
이 중간 코드가 있기에 개발자는 kotlin으로 개발하더라도, 별도의 작업을 하지 않아도 java 기반의 라이브러리를 같이 활용할 수 있습니다. 이번 이슈의 경우에도 이러한 ‘중간 코드’ 역할을 해주는 미들웨어가 있다면, 운영 난이도가 높아지고 확장성이 저해되는 경우를 피할 수 있습니다.
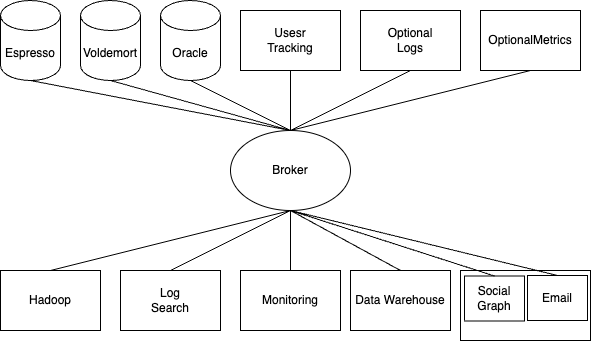
미들웨어를 활용하여 다양한 로그를 다양한 곳에 저장하는 데 필요한 관리비용을 한 곳에 집중시킬 수 있습니다.
그러나 이 방법 역시 사실 좋은 해결책은 아닙니다. data source와 data store 사이에 미들웨어 하나를 둠으로써 단일 실패 지점이 발생했기 때문입니다. 즉, 미들웨어가 shutdown 되면, 로그 자체를 저장하지 못하게 됩니다.
이러한 단일 실패 지점을 극복하려면, 결국 Broker를 Replication을 통해 leader/follower 모델을 구성해야 할 겁니다. 그런데 이러한 모델을 직접 구성하는것은 정말 어렵고 험난합니다. 사실 저는 이걸 해내려면 뭐부터 해야할지 전혀 모르겠습니다. 하지만 정말 다행인건 Jay Kreps 님께서 먼저 고민해주시고 훌륭한 오픈소스를 만들어 주셨습니다. 바로 apache kafka 입니다.
Kafka는 결국 고도화된 AsyncAppender 기반의 로깅 시스템
카프카의 기초를 설명하는 글은 아니기에 카프카의 구성 요소에 대한 설명은 생략하겠습니다.
카프카는 로그 파이프라인을 수행하는 이벤트 스트리밍 기반의 미들웨어로서, 다양한 시스템으로부터 들어오는 이벤트를 단일 포맷으로 통합시켜 적재적소의 저장소로 저장하는 이벤트를 소비하게 해주는 소프트웨어입니다.
원할한 수평 확장을 위해 로그를 파티션 단위로 분리합니다. 카프카는 파티션 단위의 순서를 보장합니다. 이러한 파티션은 브로커들에게 데이터가 복제되어 내결함성을 갖춥니다. 원본을 포함한 복제 파티션들 중 하나는 리더 역할을 하여 프로듀서가 생성하는 로그를 write하고 컨슈머가 read를 수행하고 팔로워 파티션들은 리더 파티션의 로그들을 복사하여 동기화합니다. 그러다가 리더 파티션이 죽으면 팔로워 파티션 하나가 리더로 승격되어 리더의 역할을 위임하게 됩니다.
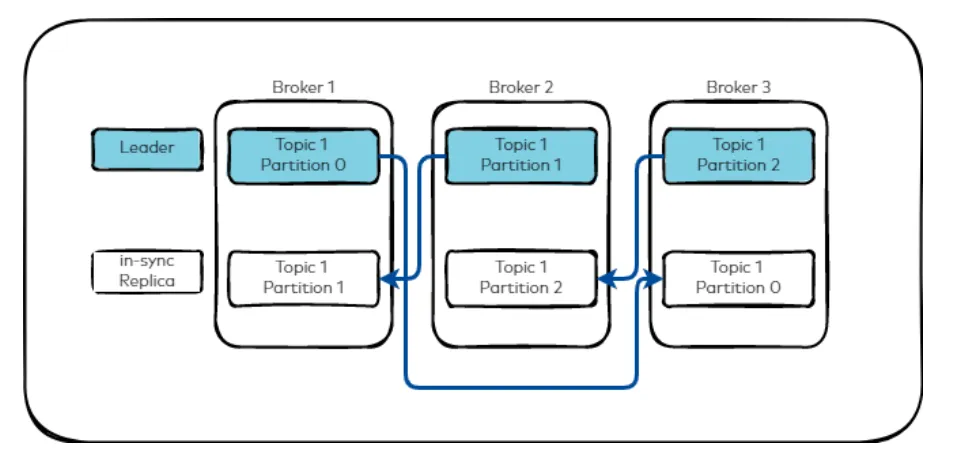
이렇게, 카프카는 주어진 설정 매커니즘을 통해 리더/팔로워 구조를 직접 하는 것보다 훨씬 직관적으로 구성할 수 있습니다.
이렇듯, 카프카는 들어오는 이벤트의 순서를 보장하고 이벤트의 로그를 기록을 비동기로 수행하여 기존 애플리케이션 시스템의 트랜잭션의 지연시간을 크게 줄여줍니다. 또한 클러스터 형성이 비교적 용이하여 위에서 언급했던 단일 실패 지점을 극복하기도 어렵지 않습니다.
Logback 라이브러리의 AsyncAppender는 로그 출력 요청을 받으면, 이벤트를 발행하여 내부의 블로킹 큐에 쌓아 worker 스레드에게 로그 출력을 위임하여, 기존 트랜잭션 스레드에 지연시간을 줄입니다. 카프카는 이렇게 AsyncAppender가 하는 역할을 대체하는 것 뿐만 아니라, 고가용성 및 내결함성을 갖추었습니다. 어떻게 보면, 카프카는 다양한 시스템을 수용하는 고도화된 Logger 라고도 할 수 있겠네요.
마무리: 그렇다면 로깅 시스템은 앞으로 카프카를 활용할까?
결론부터 말하자면, 당연히 ‘아니다’라고 할 수 있습니다. 왜냐면, 모든 서비스가 꼭 로그의 손실율을 최소화해야할 필요는 없으니까요. 또한 카프카를 사용하지 않고, 바로 ELK 스택과 같은 검증된 솔루션을 활용하는 다른 선택지도 있습니다.
마지막으로 실무에서는 상황에 따라 유지보수 효율을 낮추는 한이 있더라도 출시비용을 줄여야할 수도 있습니다. 그럴때는 모놀리식의 웹 애플리케이션에 단일 DB만 구성하고, 간단하게 Logger만 활용하는게 오히려 더 적절한 선택일 수 있습니다.
그럼에도 불구하고 제가 payment-lab 프로젝트에 카프카를 적용한 것은 2 가지의 목표가 있기 때문입니다.
- 결제 과정을 변조할 수 없는 일련의 이벤트들로 구성하고 기록하여, 정확한 결제 승인 처리 및 검색을 수행할 수 있는 환경을 만들기 위함입니다.
- 문제에 대한 근본적인 해결책과 상황에 맞는 최적의 해결책을 제시하는 유연한 사고방식의 개발자가 되는 것을 목표로 하고 있기 때문입니다.
제가 elk 스택보다는 카프카를 선택한 이유는 고가용성의 내결함성까지 갖춘 로그 시스템을 구성하는 것도 있습니다. 동시에 카프카의 파티션의 순서 보장을 활용하여 결제 상태를 이벤트로 발행하고 순차적으로 처리하는 이벤트 핸들러가 필요하기 때문입니다. 다음에는 카프카를 통해 어떻게 이벤트 스트리밍을 수행했는지에 서술해보겠습니다.
참고
'기술적 이슈 정리' 카테고리의 다른 글
| 모든 개발은 결국 도메인부터 아키텍처! (15) | 2024.11.06 |
|---|---|
| payment-lab 기술적 이슈 -3- 결제 이력 및 복구, Logger를 그대로 사용해도 되는걸까? (0) | 2023.11.17 |
| payment-lab 기술적 이슈 -2- 중복 결제를 막기위한 멱등키 생성.. 사용자가 결제를 확정짓는 시점은 언제일까? (0) | 2023.11.17 |
| payment-lab 기술적 이슈 -1- 로깅 중 비밀번호 노출의 위험성 및 대비책 (1) | 2023.11.12 |
| 정확한 결제 상태 추적 이슈 -1-, StateMachine 에 대해 알아보자 (1) | 2023.08.23 |